ACTIVE Network API Developer Blog
RSS FeedStart Earning Commissions with the Activity Search API v2
A few months back, the beta version of Activity Search API v2 made its public debut at HACKTIVE, where developers and designers put the ACTIVE APIs to the test as they innovated new ways of getting people active. Today, ACTIVE Network is proud to announce the official launch of the new Activity Search API v2 with affiliate tracking! Now, third-party developers can begin earning commissions for registrations driven through this API. The current Activity APIs will remain online for six additional months, which will give you plenty of time to upgrade your applications to the new Activity Search API v2 (see API Transition Plan below for more details).
What Is the New Activity Search API v2?
The launch of this new Activity Search API v2 will unlock loads of data and flexibility for app developers. It processes simple HTTP GET requests and returns results in JSON. The API supports keyword search against ACTIVE assets, result restriction to a particular location, and result filtering based on asset metadata. All activity registrations are completed online at ACTIVE.com. The reason this is so exciting is because we’ve also been working tirelessly to standardize our event and activity data across the company.
What Does That Mean To You?
We take event and activity data of any quality and completeness and utilize machine learning algorithms and text mining techniques to assess, clean, classify, and vastly improve the quality of the data to a form suitable for feeding into the comprehensive list of world-wide events and activities offered through Active.com. The system also ensures proper naming, categorizing, and search optimization of each event, while breaking the data down into independent sub-components, each of which can be enhanced and accessed separately. Subsequent re-submissions of these events are detected upon ingestion, de-duplicated, and smartly re-assigned the prior final changes depending on what data is new for even faster time-to-live improved data on update. No longer will you need to remove duplicate events or create special “workarounds” to pull the correct data. Basically, there will be even more events in the database and you can find the events that you are looking for more easily via the Activity Search API v2.
Enhancements Galore
Here are some of the new features you’ll find in the Activity Search API v2:
- Additional Events Available – All new events submitted to our database will be available through the Activity Search API v2. The existing Activity API will slowly receive fewer updates and less event volume. If you’re just starting to build your app, then make sure you’re building with the Activity Search API v2.
- REST Service – Supports JSON results returned by the API
- Expanded Data Set –Eliminates need for the Activity Details API making for a simpler integration
- Extra Classifications and tags – assets allow for more refined search capability using new parameters
- Combined schema – services all activity types (e.g. Camps, Classes, Races, Events)
- Standardized Attributes – e.g. Distance, Age Group
- Improved geo-location – Much improved latitude/longitude values to aid in location-based searches
API Transition Plan
All applications need to update their implementation to use the new Activity Search API v2 by August 1st, 2014— approximately six months from now. To get there in the most effective manner, here is our migration plan:
- Starting April 1st, 2014, all applications using the existing Activity API will have their rate limits slowly reduced as we have marked this API for end-of-life on August 1st, 2014.
- A rate limit of 10K calls per day will be instituted on these API keys and will be decreased by 2K calls per month until the API is sunset.
- If you register your existing (or new) application and start using the Activity Search API v2 now, you will _not_ be throttled/rate limited. We therefore highly encourage you to start using the new Activity Search API v2 keys as soon as possible.
Getting Started
Here is a quick start guide to the developer portal to help you begin building your application using an Activity Search API v2 key:
Register — http://developer.active.com/member/register
Documentation — http://developer.active.com/docs/
Interactive IO Docs — http://developer.active.com/io-docs
Developer Forum — http://developer.active.com/forum
We value our developer community and have thought about this API launch carefully. If you have any inquires, feedback, or issues related to the new API, please comment it in the forum and we’ll keep the discussion going there.
The Prediction API: An Ensemble
Building a Predictive Model
- Extract and process features from your data. For these examples, this means pulling out n-grams from our asset descriptions and vectorizing them. I'll post more about various methods for this later.
- Separate out training data to cover all your labels and a portion for testing. Here, our labels are the asset topics. There are many ways to do this, but for simplicity we just set aside a random portion of all the data.
- Run the training data through the algorithm many times with varying parameters and predict labels with your test data, assessing the model with some statistics or metrics. Repeat until your model performs to your liking.
Multinomial Naive Bayes (NB) Classifier
NB makes some assumptions, including that the probability of a feature for a particular class is independent of the probabilities of the other features for that or any other class. This is counter-intuitive. After all, wouldn't the co-occurrence of both "mud" and "run" be a better indicator of a "mud run", and isn't it unlikely that "mud" would occur without "run" in this context? Well, we capture this in part by taking n-grams of 1, 2, and 3 tokens, but the assumption of independence actually proves to be less of an issue than you might think. More importantly, it means we don't need to calculate the cross-correlation of all the features and that saves lots of processing time.
The Support Vector Machine (SVM)

Of course, there are many ways to define and draw a line, but the fastest is a straight line and the linear SVMs are quite fast. By altering variables in the algorithm, you can adjust how this line is drawn, favoring things like good overall separation (large margin) over classification mistakes in the training data (error rate). Adjusting this trade-off is called "regularization", and amounts to adjusting the size and complexity of how the margin is represented. You may still want the best separating line even if some data points are on the wrong side or in the space between. However, as you test lines, you may want to penalize these data points, and you may want to do that differently depending on what the error was. This is done with so called "loss" functions. Varying regularization and loss functions affects results, but also processing time (both in training and in testing, and not necessarily the same way).

This guarantees that there is some non-zero margin at each update and means it can also be performed online. This was an addition Google made to weed out search result spam (2004-2005) and reduced it by 50%.
Scoring
Ensembles
- Normalize the distances in the SVM models (convert them to a uniform set of percentages)
- Adjust the normalized distance by internal probabilities of being on one side or the other of the margin to help compare
- Adjust probabilities or distances by the per-label weighted F1 score achieved on testing data for each model
- Average these resulting scores over all the models to get an overall top prediction.
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import SGDClassifier, PassiveAggressiveClassifier
models = []
models.append(MultinomialNB(alpha=.01))
models.append(SGDClassifier(alpha=.0001, loss='modified_huber',n_iter=50,n_jobs=-1,random_state=42,penalty='l2'))
models.append(PassiveAggressiveClassifier(C=1,n_iter=50,n_jobs=-1,random_state=42))
from sklearn.externals import joblib
from sklearn import metrics
results = {}
for model in models:
model_name = type(model).__name__
model.fit(X_train, Y_train)
joblib.dump(model, "models/topics."+model_name+".pkl")
pred = model.predict(X_test)
class_f1 = metrics.f1_score(Y_test, pred, average=None)
model_f1 = metrics.f1_score(Y_test, pred)
model_acc = metrics.accuracy_score(Y_test, pred)
probs = None
norm = False
try:
probs = model.predict_proba(X_test)
except:
pass
if probs is None:
try:
probs = model.decision_function(X_test)
norm = True
except:
print "Unable to extract probabilities"
pass
pass
results[model_name] = { "pred": pred,
"probs": probs,
"norm": norm,
"class_f1": class_f1,
"f1": model_f1,
"accuracy": model_acc }
results
def normalize_distances(probs):
# get the probabilities of a positive and negative distance
pPos = float(len(np.where(np.array(probs) > 0)[0])) / float(len(probs))
pNeg = float(len(np.where(np.array(probs) < 0)[0])) / float(len(probs))
if pNeg > 0:
probs[np.where(probs > 0)] *= pNeg
if pPos > 0:
probs[np.where(probs < 0)] *= pPos
# subtract the mean and divide by standard deviation if non-zero
probs_std = np.std(probs, ddof=1)
if probs_std != 0:
probs = (probs - np.mean(probs)) / probs_std
# divide by the range if non-zero
pDiff = np.abs(np.max(probs) - np.min(probs))
if pDiff != 0:
probs /= pDiff
return probs
def compute_confidence(probs, labels, norm=False):
confidences = None
class_confidence = []
if norm:
confidences = normalize_distances(probs)
else:
confidences = probs
for c in xrange(len(confidences)):
confidence = round(confidences[c], 2)
if confidence != 0:
class_confidence.append({ "label": labels[c], "confidence": confidence })
return sorted(class_confidence, key=lambda k: k["confidence"], reverse=True)
def predict(txt, model, model_name, vectorizer, labels):
predObj = {}
X_data = vectorizer.transform([txt])
pred = model.predict(X_data)
label_id = int(pred[0])
predObj["model"] = model_name
predObj["label_name"] = labels[label_id]
predObj["f1_score"] = float(results[model_name]["class_f1"][label_id])
if results[model_name]["norm"]:
probs = model.decision_function(X_data)[0]
else:
probs = model.predict_proba(X_data)[0]
predObj["confidence"] = compute_confidence(probs, labels, norm=results[model_name]["norm"])
return predObj
prediction_results = []
label_scores = None
model_names = []
txt = "This is a tough mud run. Tough, as in, this could be one of the hardest events you, as a runner have ever attempted. This is not a walk in the park. This is not your average neighborhood 5k. This is more fun than a marathon. This is a challenge. The obstacles were designed by military and fitness experts and will test you to the max. Push personal limits while running, crawling, climbing, jumping, dragging, and other surprise tasks that test endurance and strength. The race consists of non-competitive heats as well as a free kid's course for children age 5-13. Each heat will depart in a specific wave so the course doesn't get overcrowded."
for model in models:
model_name = type(model).__name__
try:
prediction_results.append( predict(txt,
model,model_name, vectorizer, unique_topics))
model_names.append(model_name)
except Exception, e:
print "Error predicting" + str(e)
pass
prediction_results
from operator import itemgetter
conf_labels = {}
scored_labels = {}
for prediction_result in prediction_results:
if "label_name" in prediction_result:
l_name = prediction_result["label_name"]
f1_score = prediction_result["f1_score"]
conf = [ float(c["confidence"]) for c in prediction_result["confidence"] if c["label"] == prediction_result["label_name"] ]
if len(conf):
conf = conf[0]
else:
conf = 0
# update with confidence weighted by f1
#variations are to *= f1_score, or update confidence with just the confidence
if l_name in scored_labels.keys():
conf_labels[l_name] += f1_score * conf
scored_labels[l_name] += f1_score
else:
conf_labels[l_name] = f1_score * conf
scored_labels[l_name] = f1_score
labels_sorted = sorted(scored_labels.iteritems(),key=itemgetter(1),reverse=True)
labels_pred = []
# compute ensemble averages
num_models = len(models)
for i in xrange(len(labels_sorted)):
label = labels_sorted[i][0]
label_avg_f1score = float("%0.3f" % (float(labels_sorted[i][1]) / num_models))
label_avg_conf = float("%0.3f" % (float(conf_labels[label]) / num_models))
label_score = float("%0.3f" % (label_avg_f1score * label_avg_conf))
labels_pred.append({ "label": label, "score": label_score })
labels_pred = sorted(labels_pred, key=lambda k: k["score"], reverse=True)
labels_pred
- Wikipedia does pretty good with its Naive Bayes page and the references therein. scikit-learn has a good description, as well.
- The OpenCV SVM intro page is pretty clear. scikit-learn explains SVMs, too.
- Wikipedia is concise and clear on SGD. scikit-learn's page is here.
- The canonical reference for online PA.
The Prediction API: A new Data Science service
First, a little background. [tldr]
Asset Processing Overview
Asset Topics
Prediction API
Right tools for the job
- → Can process 200k or more documents rapidly (in seconds) for vectorization (n-gram counts, tf/idf, scaling, SVD/PCA, hashing, etc.)
- → Offers lots of well-maintained and vetted algorithms for classification (SVM and linear SVM, self-organizing maps and other neural network methods, Bayes and other statistical and probabilistic learning techniques, tree-based methods, etc.)
- → Provides measures of performance, parameter sweeping, and lots of stats
- → Enables multiclass (as opposed to binary) and multilabel (“green” and “fast” as opposed to “green” or “fast”) prediction options
- → Amenable to a prediction ensemble setup (combining different algorithms)
- → Sparse matrices support
- › 150k assets with 20k features = 3x10^9 matrix members
- → Optimized parallel processing (threads and processes)
- › We need models in minutes and predictions in milliseconds
- → Fast to support inclusion of prediction in the asset processing workflow, or any other place
- → Support for proxy and reverse proxy (like nginx)
- → Security
- → JSON support
- → Pre-forking and event loop support
- → As new data comes in
- › reach a threshold
- › rebuild models
- › self-assess
- › plug and deploy or rebuild with new parameters
- → As issues arise
- → Unsupervised clustering
- → similarity algorithms for recommendations
- → custom classification and clustering algorithm development
- → Devs without a data science background should be able to:
- › plug in new DS-derived functions
- › create new web server routes and API endpoints
- › adjust API output
- › add and apply basic stats and counting
- › code review
- → Data scientist devs should be able to extend it easily
Java
Ruby
R and MATLAB
Combos
Python
{ "event": { "topic": "Hip Hop dance", "text": "Pre-School Tumbling/ Hip Hop " } }
{ "event": { "topic": "Distance running", "text": "Santito Youth Talent Ministry Mile Run/Walk " } }
{ "event": { "topic": "Yoga", "text": "Pre/Post-Natal Yoga M Yoga is an ideal form of exercise before, during, and after pregnancy, and is safe and nurturing, Maintain strength and flexibility, combat fatigue, swelling, back ache and nausea, calm nerves and increase relaxation while reducing common discomforts. Moms and babies welcome. Instructor: Dana Chamblin. " } }
{ "event": { "topic": "Dance", "text": "Cardio Line Dancing at Haines This activity takes line dancing to a whole new level. Get a cardiovascular workout and learn a variety of moves and experience many genres of music. " } }
{ "event": { "topic": "Distance running", "text": "The 32nd Annual Skunk Cabbage Classic Run Preregistration: $20, must be postmarked by Friday, February 15, 2013; $25.00 from February16, 2013-April 8th, 2013. Race day registration $35 until 9:45 a.m. race day. " } }
{ "event": { "topic": "Photography", "text": "Photography Class with Ron St. Germain Whether your camera is an old one from the closet or the newest technology, this class will familiarize you with all of its buttons and functions. You will learn the basics in a fun and easily understood way with entertaining slide presentations and plenty of time to ask questions each week from 5-time International Award winning outdoor photographer, Ron St. Germain. For detailed information, check his website at www.daphotodude.com . " } }
{ "event": { "topic": "Creative writing", "text": "Memoir Writing (6/27-7/18) Memoirs are your memories. Learn how to convert your memories into interesting stories to pass down to future generations. Participants will learn how to connect with the great, great, great grandchildren that they will never meet and show them what their lives were like. " } }
{ "event": { "topic": "Yoga", "text": " Fall Exercise, 01a Mommy Me (Mon) " } }
import json, re
def clean(txt):
#clean your data (strip tags, remove number-only words, etc.)
return txt
def loadCorpus(data_file):
labels = []
texts = []
#load your data
events = open(data_file).readlines()
cnt = 0
processed = 0
for d in xrange(len(events)):
cnt += 1
event = re.sub(r'(\n|\r)+','',events[d].strip())
try:
json_event = json.loads(event, 'utf-8')
event = json_event["event"]
labels.append(event["topic"])
texts.append(clean(event["text"]))
processed += 1
except Exception, e:
pass
print str(processed) + " events processed out of " + str(cnt) + " (" + str(float(processed)/float(cnt)) + ")!"
return labels,texts
labels_train,data_train = loadCorpus("topics_events.json")
import numpy as np
# index the topics, getting unique entries with Python's set object
unique_topics = list(set(labels_train))
unique_topics.sort()
labels_train = np.array(labels_train)
labels = np.empty(shape=labels_train.shape)
for c in xrange(len(unique_topics)):
# use numpy's where function to find and index topics
labels[np.where(labels_train == unique_topics[c])] = c
X_train = data_train
# set aside test data using about 5% of the full data set
data_len = len(X_train)
tsn = int(data_len*0.05)
# generate a random set of indexes to pluck out for testing
test_samp = np.random.randint(0,data_len,tsn)
# use Python's list comprehension so pull out test data and labels
X_test = [ X_train[i] for i in test_samp ]
Y_test = [ labels[i] for i in test_samp ]
# remove the test data from the training data
Y_train = list(labels)
for s in sorted(test_samp,reverse=True):
del X_train[s]
del Y_train[s]
print str(len(X_train)) + " training docs, " + str(len(X_test)) + " testing docs"
print "Topics:"
[str(ut) for ut in unique_topics]
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(stop_words='english',charset_error='ignore',ngram_range=(1,3),min_df=2)
X_train = vectorizer.fit_transform(X_train)
X_train
X_test = vectorizer.transform(X_test)
X_test
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=.01)
model.fit(X_train, Y_train)
from sklearn.externals import joblib
joblib.dump(model, "models/topics.MultinomialNB.pkl")
# do the prediction
pred = model.predict(X_test)
print pred
# get some performance metrics
from sklearn import metrics
# scores per class, output not printed here to save space
#print metrics.f1_score(Y_test, pred, average=None)
#print metrics.recall_score(Y_test, pred, average=None)
#print metrics.precision_score(Y_test, pred, average=None)
# overall scores
print metrics.f1_score(Y_test, pred)
print metrics.accuracy_score(Y_test,pred)
# performance by topic
print metrics.classification_report(Y_test, pred,target_names=unique_topics)
print "Confusion Matrix:"
print metrics.confusion_matrix(Y_test, pred)
from bottle import Bottle, run, request, abort, error,HTTPResponse, HTTPError
# initialize the server
app = Bottle()
# define a route to take some GET data
@app.route('/pred/topic/<text_data>')
def runPrediction(text_data=''):
pred_results = {}
probabilities = []
pred = None
probs = None
pred_results["data"] = text_data
topic_nm = ""
topic = None
try:
X_data = vectorizer.transform([text_data])
# rerun prediction to get probabilities
if "predict_proba" in dir(model):
try:
probs = model.predict_proba(X_data)[0]
topic = np.argmax(probs)
except:
pass
else:
pred = model.predict(X_data)
topic = int(pred[0])
topic_nm = unique_topics[topic]
except:
pass
if probs is not None:
for pr in xrange(len(probs)):
prob = round(probs[pr],2)
# only show if the probability is > 0
if prob > 0:
probabilities.append({ "topic": unique_topics[pr], "confidence": prob })
pred_results["confidence"] = sorted(probabilities, key=lambda k: k["confidence"], reverse=True)
pred_results["suggestion"] = { "topic": topic_nm, "confidence": round(probs[topic],2) }
return json.JSONEncoder().encode(pred_results)
# start the server
# hit "http://localhost:3000/pred/topic/I like to run with my socks on and in the rain with a soccer ball and umbrella ok" to predict on that text
run(app, host="localhost", port=3000, debug=True)
Lessons Learned in API Development
Be Explicit
Separation of Concerns
Don't Tie Your API To A Specific Technology
m=meta:assetId=96d1c440-425d-4dfe-af97-cba325ae73b7 AND meta:city=San%2520Diego
Be Consistent
<channel>Running</channel>
<channel>
<value>Running</value>
<value>Cycling</value>
</channel>
<results>
<result>
<meta>
<eventState>CA</eventState>
<channel>
<value>Running</value>
</channel>
"_results": [
{
"meta": {
"state": "CA",
"channel": "Running,
Eat Your Own Dog Food
Russian Doll Caching with Elasticsearch
Here at Active, we eat our own dog food, which means our primary data store for information about our events on Active.com comes through the same API that you all use. We’re also religiously focused on improving the load times of our applications, especially of Active.com itself. For those of you who don’t know, Active.com is a ruby application, built with Rails. Like most frameworks, Rails can lose a lot of time to compiling it’s view templates with new information, and we’re no exception. On our event details pages, we spend an inordinate amount of time doing so, then cache it at Memcached for ~15 mins, which helps the overall response times (and during high traffic events). However when people request an event that isn’t already stored at this cache that full recalculation has to occur, which hurts our 98th percentile numbers, and more importantly hurts our users who just come to check out a new event.
This is all made more complicated by the fact that each of our event assets have child assets representing sub events, pricing information, etc. Rails 4 solved this problem by implementing Russian Doll Caching (a nested form of generational caching explained well here). Obviously this would be our first choice, however we would rather avoid linking directly to our database, as we prefer to continue eating our own dog food.
We did come up with a solution, a way to implement the Russian Doll cache on our site and expose it to you all too! The _version field in an ElasticSearch document provides a definitive version for a document. Thus we are now passing that through our api in a new field called “assetVersion” you’ll find in your api calls to Activity Search v2. All children of a given asset will now either be indexed with new guids or their versions will be incremented when they are changed. Roll the cache digests gem in, and you can now construct a functional Russian Doll Caching scheme backed by ElasticSearch.
class EventController < ApplicationController
def show
@event = ACTV.event params[:id]
end
end
<% cache("event/#{@event.id}/#{@event.assetVersion}") do %>
<!-- Display Event Information -->
<% @event.components.each do |component| %>
<% cache("component/#{component.id}/#{component.assetVersion}") do %>
<!-- Display Individual Component Information -->
<% end %>
<% end %>
<% end %>
So now if the event itself is changed, it will bump the document version without changing the children. So just the section displaying that event information will have to be recompiled, while the others are drawn from Memcached. If the components (in this case the subevents and their pricing) are altered, that individual subevent will fall out due to either it’s guid or it’s document version changing, and the parent document will fall out due to us reindexing it (which bumps it’s assetVersion). Thus only that one subcomponent will be recompiled and the general information will be recompiled while everything else is drawn from Memcached. Additionally the inclusion of the cache digests gem will ensure that your cache keys have the digests of the views appended to the end of them.
Hopefully this will help you if you’re using our Activity Search v2 API or simply if you’re using ElasticSearch as a datastore in your application!
ACTIVE Network's HACKTIVE Hackathon Winners
HACKTIVE, part of the ACTIVE Next program, was a big success and the first ever event of its kind for ACTIVE, which allowed the public to participate in a company event. Nearly 50 developers joined us over the weekend to hack ACTIVE’s APIs. Saturday morning kicked-off with a keynote from Mark Roebke, Director of Product Innovation at ACTIVE and the brain behind the ACTIVE Next Program. Mark got participants revved up with stories of innovation before the judges were introduced
We had an all-star line-up that included industry leaders from: Mashery, Yahoo!, Aetna, TAO Venture Capital Partners and ACTIVE. The competition started at noon and contestants had 24-hours to develop an original app that was relevant to the theme of getting more people active. Teams came pouring into Co-Merge in downtown San Diego, CA to get setup and find a spot to start hacking. They had help from Neil Mansilla, Director of Developer Platform & Partnerships at Mashery, Cheston Contaoi, President of Driveframe LLC, and Jarred Doss, Product Manager & Developer Evangelist at ACTIVE, who coached and supported contestants through the initial stages of inception, creation and design. They did a great job motivating developers and helping them polish their hacks to prepare for final presentations.

Hackers were doing everything they could to stay awake and comfortable through the 24-hour competition. As the hours passed, snuggies and onesies were used to keep comfy, while others decided to load up on cardiac arrest-enducing amounts of energy drinks.

The hackathon proved too much for event emcee, Jon Christopher. He couldnt hack it and fell asleep under the warm glow of the neon HACKTIVE sign. HACKTIVE coach, Cheston Contaoi, and hacker, Eric Johnson, balanced Oreo cookies on thier faces just for fun. Watch the video to find out what really happened - Cheston & Eric. There was even a visit from the ghost of HACKTIVE future. There were a few teams that continued to hack all through the night without any shut-eye.

On Sunday morning, teams begin to focus on finishing up their apps and preparing their presentations. At noon, the contestants presented their apps to the judges. There was an interesting mix of ideas, from getting gamers more active to using activity data to make romantic connections. Winners included:
ACTIVE Staff:
-
1st place: ACTIVE Graph
- Created by Tyler Clemens, Eric Johnson, Trey Gorman & Kevin Brinkley (from left to right in photo below). Social networks like Facebook are mapping the social graph. ACTIVE Network has the ability to take this a step further and map the activity graph--the relationships between users, their friends, their interests, and the activities in which they participate. Making this graph available across the organization as an enterprise service, using a graph database like Neo4J, opens up a whole new category of connections that can be explored. Two applications of the graph were demonstrated: 1) recommending networking or meet-up opportunities at an event based on these connections and 2) making targeted event recommendations to users based on friends' interests and activities. Mapping these new connections allows event organizers, media, and ACTIVE Network the ability to leverage this new data to create valuable market opportunities across all of ACTIVE’s platforms.

-
2nd place: Spark
- Created by Caitlin Goldman, Jared Planter & Evan Witte (from left to right in photo below). Spark YOUR Training, Spark YOUR Life. This app allows users to create a profile, add interests and event history, and search for events using ACTIVE’s Activity Search API. It gives you the ability to connect with other users that have similar interests and automatically drives romantic connections based on your ‘spark’ potential. Based on the average user spend in the online dating community, this has huge market value if executed correctly.

-
3rd place: ACTIVE Analyze
- Created by Bob Charapata, Daniel Middleton, Jeff Sample & Ryan Sappenfield (no photo, remote team). An Active Network Intranet web application leveraging Microsoft SharePoint self-service business intelligence tools to analyze obesity rates vs. activity participation and other health data. The application queries, in real-time, Active and Mashery API's to return results that are then transformed and loaded into a data model. Users can then create reports and visualizations using a variety of end user BI tools, including; Excel, Power View, Power Pivot and a new Power Map 3D map tool. This data can be used to find new business insights and market opportunities for ACTIVE Network.
Non-Collegiate:
-
1st place: Sports & Dating
- Created by Bo Li. Sports & Dating is an activity-based dating app, matching singles through sports. Presents your favorite sporting events in the map via the ACTIVE Activity Search API, see how many potential matches have joined the event, then see who is going to the event you are interested in and connecting with others. This app will help to make a dating decision easy and instantly. This will also maximize your chance of meeting someone at an event.

-
2nd place: Get me ACTIVE!
- Created by Joel Drotleff. Fully native iOS 7-optimized app to help people search for activities near them, such as biking, little league, running, and more. Makes it easy to visualize events with topic icons on a map (i.e. runner icon for running type events). Once the user has been to an event, they can reward themselves with a badge and picture to remember their accomplishment.

-
3rd place: Phat ACTIVE
- Created by Bret Stateham. Allows users to find events, invite their friends, and then challenge them to a distance run prior to the event. Integrates fitness tracking devices to track challenges prior to the event.

Collegiate:
-
1st place: ACTIVE Calendar
- Created by Hoa Mai & Nhu-Quynh Liu. Active Calendar allows the user to search for active events on specific dates by simply clicking a day and entering their search keywords. Future plans to integrate external calendars (iCal, Google Calendar, etc) to allow users to plan their activities around their busy lives.
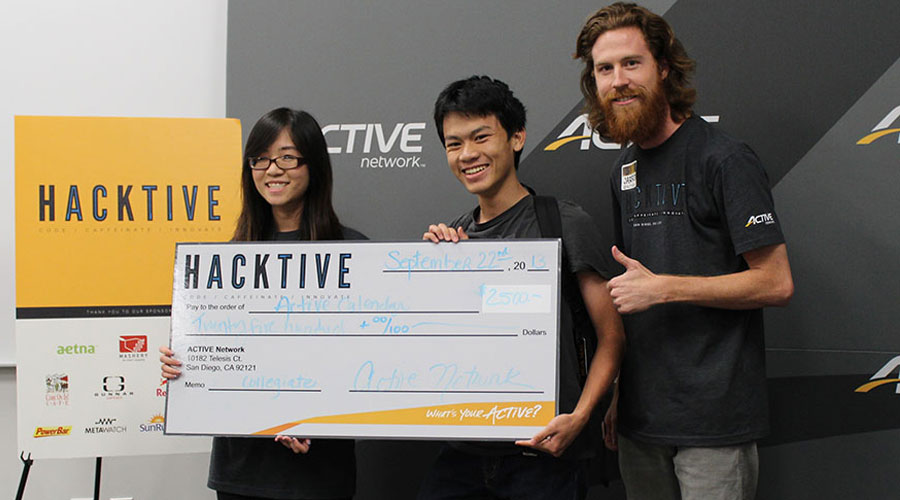
-
2nd place: ActiBar
- Created by Pablo Jacome, Yevgeniy Galipchak, Atyansh Jaiswal, Wonsik Min & Alexander Saavedra (from left to right in photo below - Alexander Saavedra was unable to attend the demo). A simple browser add-on or application that makes it easier for the user to find local physical activities that may range from marathon runs, to simple pickup games in various sports. The user will be able to customize their news feed of activities through a series of personalization questionnaires, in which different activities will be presented depending on the time and location of the user.

-
3rd place: ACTIVE IT
- Created by Vyshakh Babji & Bharath MylarappaConnect with people around you instantly. Match your interests, contact people in realtime and have fun. Sends an SMS text message when other users signup and select a similar event in your area. Be ACTIVE with others!!!

Mashery Prize:
- The Mashery Prize was won by & Ronad Castillo for effectively using one of the Mashery API Network APIs to build ACTIVEnieghbor - an app that allows users to connect with like-minded individuals within a certain radius that share a similar fitness goal and schedule a time to workout. User-created events are mixed with ACTIVE Network's events and users are gouged into persistent/anonymous chat to discuss goals and schedule a time to train. The app notifies all users and schedules the events on their calendars allowing for organic social growth based on proximity.
- Aaron Waldman also won the Mashery Prize for creating the ACTIVE Leaderboard. His app takes a new look at race results. Now organized into a leaderboard with the users Facebook friends, pulling in their race results for comparison. Now you can compare your fastest 5k against your friends, or at the same event.

You can view all the app submissions online at ChallengePost.
Special thanks the sponsors of the event and the guest judges, Erik Suhonen, Jesse Givens, Neil Mansilla, Tom Clancy, and Mark Roebke for offering your expertise and guidance. Of course, a huge thanks to everyone that participated! We couldn't have made the event a success without the hackers. This beta event gave us a lot of key learnings that will allow us to replicate the model and host a global hackathon in the future.
You can view all the photos and videos here: http://www.flickr.com/photos/103184269@N08/
HACKTIVE 2013 starts in 2 days, get ready!!
|
Hackers get ready! We can't wait to see you this Saturday at HACKTIVE 2013, ACTIVE Network's first 24-hour hackathon event. We hope you are as excited as we are to start hacking the night away, here are some things you should know before you arrive on Saturday... LOCATION Co-Merge Workplace 330 A Street San Diego, CA 92101 CHECK-IN Saturday, Sept. 21 @ 10:00AM (get there early and claim your space!) PARKING We suggest parking in the garage on Ash between 3rd & 4th Avenue. Rates vary between $5-$12/day. Find parking details here: http://www.co-merge.com/parking-at-co-merge/ (Note: parking will NOT be validated--sorry!) ACCESS THE ACTIVE APIs
APP SUBMISSIONS You'll need to submit your application here http://hacktive.challengepost.com by the 12pm/noon deadline on Sunday, September 22. Submissions need to include the following (*optional):
PACE YOURSELF & COME PREPARED
UNDERSTAND HOW TO WIN
http://developer.active.com/blog/read/How_the_ACTIVE_API_Has_Helped_Win_Hackathons http://masherydev.tumblr.com/post/27076593127/api-hackday-dallas-july-1-2012 http://developer.active.com/blog/read/7_steps_to_success_advice_every_hackathon_attendee_should_hear http://appsembler.com/blog/10-tips-for-hackathon-success/ http://www.intridea.com/blog/2012/6/4/five-tips-for-hackathon-participants http://blog.mashape.com/post/53975325208/how-to-find-app-ideas-for-hackathons http://alexstechthoughts.com/post/28836325740/how-to-win-a-hackathon http://www.quora.com/Hackathons/Attending-a-hackathon-for-the-first-time-Tips |
Coders Gear Up for HACKTIVE, ACTIVE Network 24-Hour Hackathon
HACKTIVE, ACTIVE Network’s first public hackathon, officially opens its doors in less than two weeks. The 24-hour event will take place September 21st, 2013 to September 22nd, 2013 at Co-Merge in San Diego, California. Developers, designers and entrepreneurs will mashup the ACTIVE APIs along with other datasets as they innovate ways of using technology to connect people with activities and ultimately make the world a healthier place.
In addition to being a breeding ground for innovation and inspiration, the hackathon offers attendees the chance to help make a difference, flex their skills, and compete for over $15k in prizes! Here’s just a taste of what participants have in store:
- Two days of intensive collaboration, creativity and caffeination
- An abundance of food, drinks, snacks, and caffeine…thanks to our awesome sponsors
- Feedback from industry experts in both the local and national tech community
- Inspiring keynote along with exciting live demos
- On-site mentoring from passionate hackathon coaches
- HACKTIVE t-shirt to score some street cred
- Opportunity to network with accomplished developers as well as up-and-coming tech talents
- In-person tech support to help troubleshoot
- Fun and energizing interludes plus some sweet swag giveaways
After the submission phase is complete, teams will have three minutes to present their app. Winning hacks will be determined based on four equally-weighted criteria including design, effective use of the ACTIVE Network platform, utility, and originality of concept. Demos take place in two rounds, where the top teams will advance and battle it out before a panel of industry experts. Here’s a glimpse at the lineup:
| Erik Suhonen - Head of Yahoo! Developer Network, Yahoo! | Erik is responsible for managing a vibrant, global ecosystem of 600,000+ technology companies who engage with Yahoo!'s 30+ platforms. | |
| Neil Mansilla - Director of Developer Platform & Partnerships, Mashery | Neil is a passionate software engineer and responsible for helping developers discover, learn and utilize the APIs on the Mashery API network. | |
| Jesse Givens – Head of Product for CarePass, Aetna | With CarePass, Aetna offers all consumers a solution to achieve their unique wellness goals by connecting to top mobile apps. |
It’s not too late to sign up, so make arrangements to meet us there! Register Now: http://developer.active.com/hackathon_2013
Follow us on Twitter @activeapi for the latest event updates!
How the ACTIVE API Has Helped Win Hackathons in 2013
 HACKTIVE is less than a month away, and we couldn’t be more excited for this 24-hour frenzy of coding, collaboration, and caffeine! While this may be ACTIVE Network’s first public hackathon, when it comes to the ACTIVE API, this ain’t its first rodeo. In fact, the Activity Search API has been used to build award-winning apps at numerous hackathons this year alone. Mashery has covered a few of them including last week’s MoDev Hackathon in Seattle, where Bethany Rents (@bethanyrentz) used the Activity API to build her prizewinning app. Built in C# for Windows tablets, To the Finish transforms the experience of training for a marathon or any running event into a social one.
HACKTIVE is less than a month away, and we couldn’t be more excited for this 24-hour frenzy of coding, collaboration, and caffeine! While this may be ACTIVE Network’s first public hackathon, when it comes to the ACTIVE API, this ain’t its first rodeo. In fact, the Activity Search API has been used to build award-winning apps at numerous hackathons this year alone. Mashery has covered a few of them including last week’s MoDev Hackathon in Seattle, where Bethany Rents (@bethanyrentz) used the Activity API to build her prizewinning app. Built in C# for Windows tablets, To the Finish transforms the experience of training for a marathon or any running event into a social one.
 Back in April, two Rutgers students took the title for “Best Use of an API from the Mashery Network,” at the 24-hour student hackathon, HackRU. “Let’s Plan Gen!” built by Joyce Wang and Nikolay Feldman, is an android app that connects users to local happenings, saves ones of interest, and then creates a schedule based on the user's selections. The duo “decided to choose Active because sports activities around the area are not always well-known and publicized enough.” Without any prior experience doing Android programming, both Wang and Feldman found the ease and efficiency of the Activity Search API to be a key component of their success.
Back in April, two Rutgers students took the title for “Best Use of an API from the Mashery Network,” at the 24-hour student hackathon, HackRU. “Let’s Plan Gen!” built by Joyce Wang and Nikolay Feldman, is an android app that connects users to local happenings, saves ones of interest, and then creates a schedule based on the user's selections. The duo “decided to choose Active because sports activities around the area are not always well-known and publicized enough.” Without any prior experience doing Android programming, both Wang and Feldman found the ease and efficiency of the Activity Search API to be a key component of their success.
 And who could forget CouchCachet—the most convenient way of fooling your friends into thinking you’re cooler than you actually are. The mobile app was the Mashery grand prize winner at the foursquare hackathon earlier this year, and created with the help of (wait for it...) the Activity Search API. Harlie, CouchCachet developer explained “CouchCachet allows you to pretend you have a life by checking you in around town while you're still at home. We then send you a follow up email the next day which contains suggestions for real activities you may want to try doing. We used your ACTIVE API to populate this email. It was super easy to use (thanks!) and helped us win the NYC Mashery prize... and were featured in PandoDaily." The team was awarded the opportunity to attend SXSW Interactive and showcase their app in the center ring at Circus Mashimus.
And who could forget CouchCachet—the most convenient way of fooling your friends into thinking you’re cooler than you actually are. The mobile app was the Mashery grand prize winner at the foursquare hackathon earlier this year, and created with the help of (wait for it...) the Activity Search API. Harlie, CouchCachet developer explained “CouchCachet allows you to pretend you have a life by checking you in around town while you're still at home. We then send you a follow up email the next day which contains suggestions for real activities you may want to try doing. We used your ACTIVE API to populate this email. It was super easy to use (thanks!) and helped us win the NYC Mashery prize... and were featured in PandoDaily." The team was awarded the opportunity to attend SXSW Interactive and showcase their app in the center ring at Circus Mashimus.
If you haven’t done so already, you should make plans to join us next month at HACKTIVE. Not only will you be competing for a worthy cause, but you’ll also get to hack against the new Activity Search API v2! Now, developers have access to even more events as well as additional flexibility in how they retrieve the data. No matter your skill level, sign up and take part in the awesome innovation happening over the weekend of September 21st-22nd.
We’ll see you in San Diego!
For more information on HACKTIVE or to register, visit http://developer.active.com/hackathon_2013.
7 steps to success: advice every hackathon attendee should hear
Now that registration is officially open for HACKTIVE, our upcoming hackathon event, time is of the essence. With only 24 hours to build your app, how you prepare can make or break your chance at the podium. If you plan to join us this September or are gearing up for another event, there are several measures you can take to maximize your chance at success once the clock starts ticking. Past hackathon champs offer up some of their winning tips:
- Book early. Have you already registered for HACKTIVE? If so, you’re off to a good start. Despite the upsurge in hackathons happening around the globe, it’s not unusual for events to fill up soon after they are announced.
- Find libraries in a language you’re comfortable with. “Sometimes API providers aggregate these on their developer site, but searching github usually does the trick too,” explains Microsoft technical evangelist, Stacey Mulcahy.
- Carefully review the available data sets. Mulcahy also advises developers to “find obscure or interesting API that has lots of data – it will give you more options than an API that has limited endpoints and data.”
- Make lists. “Have a list of interesting data sources, tools, and ideas before going into a hackathon,” suggests Dan Schultz, creator of the winning hack at the recent Knight-Mozilla Open News Hack Day event. “You can use these to brainstorm new ideas with a team, or just pick a single mission and run with it."
- Mitigate against an unstable API that could possibly jeopardize your presentation. Winner of two hackathons, James Rutherford, uses his past failure as an example for why it’s important to plan for the worst. “If you see this is a risk, you have the time, and it suits the scope, then you could mock up some quick and dirty fake local stubs to mimic the API. It’s worth your while capturing some API responses during the event for appropriate endpoints so you can swiftly cludge this if pushed.”
- Take into account how interoperable the API is. Rutherford also recommends to “take time out early on to take a close look at the responses from the APIs, to ensure they’re all usable. For example, there are a raft of ways to specify geolocations – you should ensure that the data formats match the other intended APIs and presentation layers (e.g. map visualisations), or at the least- that you can afford the time to convert between them.”
- Know the access limitations. A final piece of advice from Rutherford cautions developers to be cognizant of the API request rates and any other types of restrictions they may have. “Some have daily limitations, which could hamper the completion of your project at a late stage- local mockups would be useful here too.”
Check out the full article on Programmable Web: Advice from Hackathon Winners: How to Plan Your Time and Choose the Right APIs
Have you participated in a hackathon before? If so, share some of your tips in a comment below!
[ Page 1 of 5 | Next ]
